TensorFlow - Custom Object Detection API
Contents
Tutorial ini adalah lanjutan dari tutorial TensorFlow - Object Detection API yang membahas tentang penggunaan API untuk deteksi objek menggunakan TensorFlow, pada tutorial sebelumnya terdapat permasalahan yaitu objek yang dikenali hanya objek umum saja dan model yang kita gunakan adalah model yang sudah di-training oleh seseorang yang kita tidak tahu bagaimana prosesnya, maka pada tutorial ini menjawab pertanyaan pada tutorial sebelumnya yaitu “Bagaimana jika kita ingin mendeteksi objek khusus yang kita tentukan sendiri?”.
Tutorial ini membahas bagaimana cara menggunakan objek yang kita tentukan sendiri yaitu pada kasus ini adalah deteksi objek Tanda Nomor Kendaraan Bermotor (TNKB) atau yang sering disebut Plat Nomor.
Mempersiapkan Dataset
Jika kita ingin mengenali objek “khusus” yang ingin kita deteksi, tentu kita memerlukan dataset untuk proses training, sehingga Neural Network yang akan kita latih untuk mengenali objek tersebut dapat mengenali objek yang kita maksud. Penulis sudah menyiapkan dataset yang kita butuhkan yaitu dataset gambar Plat Nomor sebanyak 502 beserta annotationnya, 472 untuk training dan 30 untuk testing/validation. Namun jika anda bermaksud untuk mendeteksi objek yang anda tentukan sendiri silahkan mengumpulkan dataset tersebut minimal 100 gambar.
Jika ingin menggunakan dataset yang sudah penulis siapkan silahkan unduh disini yang berukuran 102MB. Unduh file annotations.zip dan images.zip saja dan langsung ke tahap Training. Tapi jika ingin menggunakan dataset sendiri langsung menuju tahap Membuat Annotation dibawah ini.
Membuat struktur direktori
Struktur direktori berikut ini digunakan untuk menyimpan konfigurasi dan dataset annotation maupun gambar yang akan kita gunakan untuk proses training
$ mkdir data
$ mkdir {images,annotations}/{train,test}
Membuat Annotation
Untuk memuat annotation atau memberikan label pada gambar kita akan menggunakan aplikasi LabelImg yang nantinya akan disimpan kedalam file XML dengan format PASCAL VOC
Cara membuat anotasinya :
- Buka aplikasi
labelImg - Klik tombol “OpenDir”
- Pilih direktori dataset gambar
- Klik tombol “Create RectBox” untuk membuat kotak area objek yang akan dikenali
- Arahkan kursos dan tarik area kotak disekitar objek
- Lalu akan muncul kotak dialog untuk memberikan nama label dari objek yang akan kita kenali
- Simpan hasil pelabelan dengan menekan tombol
CTRL+S - Pilih direktori penyimpanan file hasil pelabelan
*.xml
Note: Nama label objek yang dikenali harus sama
Case Sensitive.
Simpan hasilnya kedalam direktori yang sama dengan data gambar
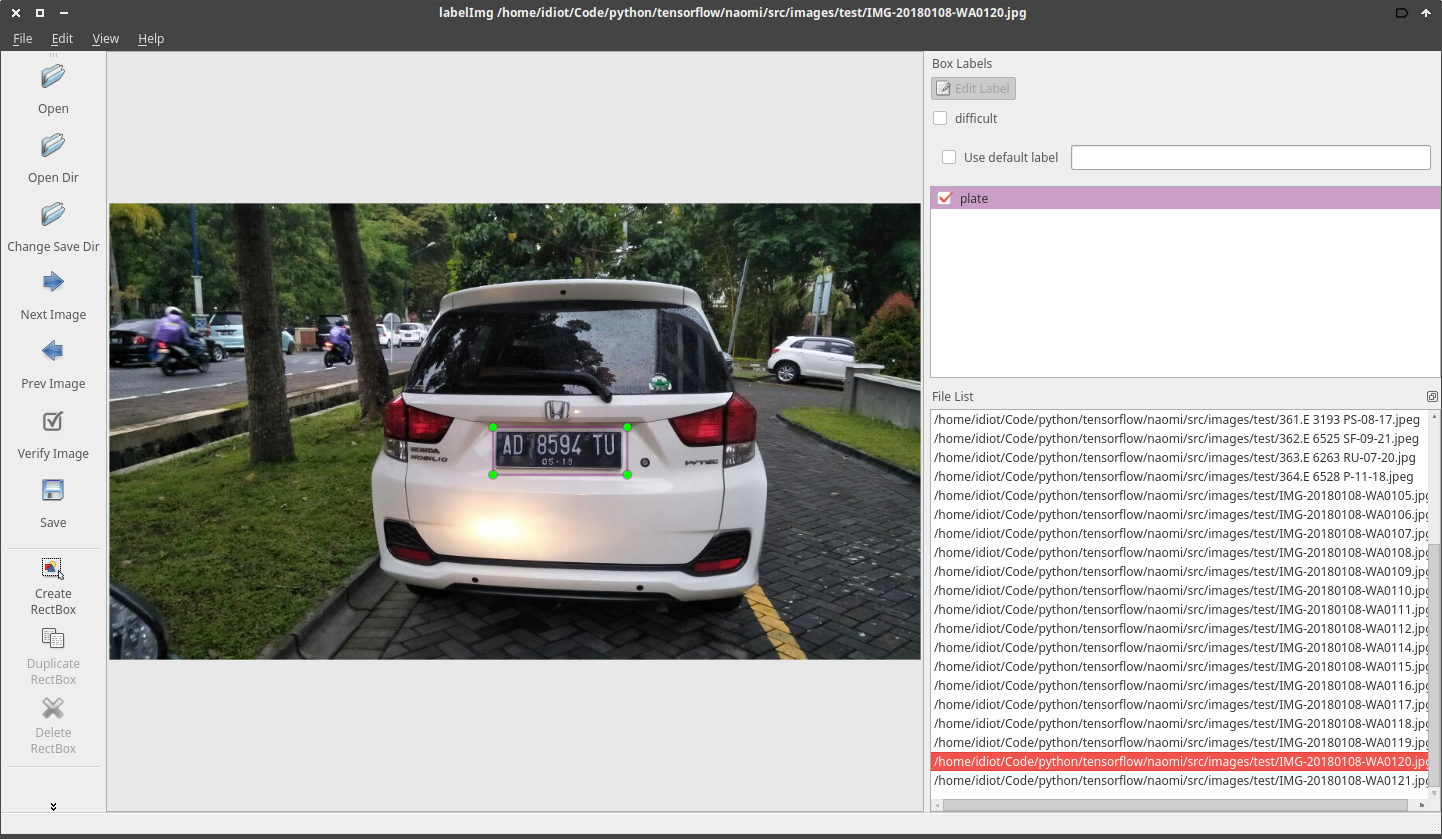
Convert XML ke CSV
Dataset annotation yang kita buat diatas menggunakan aplikasi labelImg perlu dikonversi dari format .xml ke .csv yang nantinya akan digunakan untuk mengenerate berkas TFRecord, berikut kode untuk mengkonversi format berkas yang kita butuhkan
import os
import glob
import pandas as pd
import xml.etree.ElementTree as ET
def xml_to_csv(path):
xml_list = []
for xml_file in glob.glob(path + '/*.xml'):
tree = ET.parse(xml_file)
root = tree.getroot()
for member in root.findall('object'):
value = (root.find('filename').text,
int(root.find('size')[0].text),
int(root.find('size')[1].text),
member[0].text,
int(member[4][0].text),
int(member[4][1].text),
int(member[4][2].text),
int(member[4][3].text)
)
xml_list.append(value)
column_name = ['filename', 'width', 'height', 'class', 'xmin', 'ymin', 'xmax', 'ymax']
xml_df = pd.DataFrame(xml_list, columns=column_name)
return xml_df
def main():
for directory in ['train', 'test']:
image_path = os.path.join(os.getcwd(), 'annotations/{}'.format(directory))
xml_df = xml_to_csv(image_path)
xml_df.to_csv('data/{}_labels.csv'.format(directory), index=None)
print('Successfully converted xml to csv.')
main()
Simpan kode program diatas dengan nama xml_to_csv.py. Lalu jalankan perintah dibawah ini untuk mengkonversi file XML ke CSV.
$ python3 xml_to_csv.py
Convert TFRecord
Pada saat proses training, pertama-tama TensorFlow akan membaca data input dan proses ini dinamakan feeding data yang dijalankan melalui fungsi feed_dictionary, fungsi tersebut secara langsung mengambil informasi dataset yang telah kita siapkan dalam format TFRecord maka dari itu kita perlu men-generate data annotation yang telah kita konversi ke .csv tadi kedalam format TFRecord. Berikut ini adalah kode untuk men-generate file TFRecord
from __future__ import division
from __future__ import print_function
from __future__ import absolute_import
import os
import io
import pandas as pd
import tensorflow as tf
from PIL import Image
from object_detection.utils import dataset_util
from collections import namedtuple, OrderedDict
flags = tf.app.flags
flags.DEFINE_string('type', '', 'Type of CSV input (train/test)')
flags.DEFINE_string('csv_input', '', 'Path to the CSV input')
flags.DEFINE_string('output_path', '', 'Path to output TFRecord')
FLAGS = flags.FLAGS
def class_text_to_int(row_label):
if row_label == 'plate':
return 1
else:
None
def split(df, group):
data = namedtuple('data', ['filename', 'object'])
gb = df.groupby(group)
return [data(filename, gb.get_group(x)) for filename, x in zip(gb.groups.keys(), gb.groups)]
def create_tf_example(group, path):
with tf.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid:
encoded_jpg = fid.read()
encoded_jpg_io = io.BytesIO(encoded_jpg)
image = Image.open(encoded_jpg_io)
width, height = image.size
filename = group.filename.encode('utf8')
image_format = b'jpg'
xmins = []
xmaxs = []
ymins = []
ymaxs = []
classes_text = []
classes = []
for index, row in group.object.iterrows():
xmins.append(row['xmin'] / width)
xmaxs.append(row['xmax'] / width)
ymins.append(row['ymin'] / height)
ymaxs.append(row['ymax'] / height)
classes_text.append(row['class'].encode('utf8'))
classes.append(class_text_to_int(row['class']))
tf_example = tf.train.Example(features=tf.train.Features(feature={
'image/height': dataset_util.int64_feature(height),
'image/width': dataset_util.int64_feature(width),
'image/filename': dataset_util.bytes_feature(filename),
'image/source_id': dataset_util.bytes_feature(filename),
'image/encoded': dataset_util.bytes_feature(encoded_jpg),
'image/format': dataset_util.bytes_feature(image_format),
'image/object/bbox/xmin': dataset_util.float_list_feature(xmins),
'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs),
'image/object/bbox/ymin': dataset_util.float_list_feature(ymins),
'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs),
'image/object/class/text': dataset_util.bytes_list_feature(classes_text),
'image/object/class/label': dataset_util.int64_list_feature(classes),
}))
return tf_example
def main(_):
writer = tf.python_io.TFRecordWriter(FLAGS.output_path)
path = os.path.join(os.getcwd(), 'images/{}'.format(FLAGS.type))
examples = pd.read_csv(FLAGS.csv_input)
grouped = split(examples, 'filename')
for group in grouped:
tf_example = create_tf_example(group, path)
writer.write(tf_example.SerializeToString())
writer.close()
output_path = os.path.join(os.getcwd(), FLAGS.output_path)
print('Successfully created the TFRecords: {}'.format(output_path))
if __name__ == '__main__':
tf.app.run()
Simpan kode program diatas dengan nama generate_tfrecord.py. Kemudian jalankan perintah dibawah ini untuk men-generate TFRecord file.
$ python3 generate_tfrecord.py --type=train --csv_input=data/train_labels.csv --output_path=data/train.record
// dan
$ python3 generate_tfrecord.py --type=test --csv_input=data/test_labels.csv --output_path=data/test.record
Membuat Label Map
Berikut ini adalah konfigurasi untuk memetakan label yang akan kita gunakan untuk memberikan penamaan pada objek yang akan kita deteksi. Jika objek yang akan kita deteksi ada lebih dari satu objek maka buat item sebanyak objek yang akan kita deteksi dan id maupun name harus menyesuaikan dokumentasi, namun pada kasus ini kita akan mendeteksi hanya untuk satu objek saja. Berikut konfigurasi label map yang akan kita gunakan
item {
id: 1
name: 'plate'
}
Simpan konfigurasi label map tersebut dengan nama plate_number_map.pbtxt kedalam folder data.
Konfiguras Pipeline
Karena tensorflow menggunakan ProtoBuf maka kita perlu membuat konfigurasi pipeline dan kita akan menggunakan konfigurasi dari SSD with Mobilenet v1 yang digunakan oleh Oxford-IIIT untuk Dataset hewan peliharaan. Contoh konfigurasi dapat dilihat disini.
model {
ssd {
num_classes: 1
box_coder {
faster_rcnn_box_coder {
y_scale: 10.0
x_scale: 10.0
height_scale: 5.0
width_scale: 5.0
}
}
matcher {
argmax_matcher {
matched_threshold: 0.5
unmatched_threshold: 0.5
ignore_thresholds: false
negatives_lower_than_unmatched: true
force_match_for_each_row: true
}
}
similarity_calculator {
iou_similarity {
}
}
anchor_generator {
ssd_anchor_generator {
num_layers: 6
min_scale: 0.2
max_scale: 0.95
aspect_ratios: 1.0
aspect_ratios: 2.0
aspect_ratios: 0.5
aspect_ratios: 3.0
aspect_ratios: 0.3333
}
}
image_resizer {
fixed_shape_resizer {
height: 300
width: 300
}
}
box_predictor {
convolutional_box_predictor {
min_depth: 0
max_depth: 0
num_layers_before_predictor: 0
use_dropout: false
dropout_keep_probability: 0.8
kernel_size: 1
box_code_size: 4
apply_sigmoid_to_scores: false
conv_hyperparams {
activation: RELU_6,
regularizer {
l2_regularizer {
weight: 0.00004
}
}
initializer {
truncated_normal_initializer {
stddev: 0.03
mean: 0.0
}
}
batch_norm {
train: true,
scale: true,
center: true,
decay: 0.9997,
epsilon: 0.001,
}
}
}
}
feature_extractor {
type: 'ssd_mobilenet_v1'
min_depth: 16
depth_multiplier: 1.0
conv_hyperparams {
activation: RELU_6,
regularizer {
l2_regularizer {
weight: 0.00004
}
}
initializer {
truncated_normal_initializer {
stddev: 0.03
mean: 0.0
}
}
batch_norm {
train: true,
scale: true,
center: true,
decay: 0.9997,
epsilon: 0.001,
}
}
}
loss {
classification_loss {
weighted_sigmoid {
anchorwise_output: true
}
}
localization_loss {
weighted_smooth_l1 {
anchorwise_output: true
}
}
hard_example_miner {
num_hard_examples: 3000
iou_threshold: 0.99
loss_type: CLASSIFICATION
max_negatives_per_positive: 3
min_negatives_per_image: 0
}
classification_weight: 1.0
localization_weight: 1.0
}
normalize_loss_by_num_matches: true
post_processing {
batch_non_max_suppression {
score_threshold: 1e-8
iou_threshold: 0.6
max_detections_per_class: 100
max_total_detections: 100
}
score_converter: SIGMOID
}
}
}
train_config: {
batch_size: 4
optimizer {
rms_prop_optimizer: {
learning_rate: {
exponential_decay_learning_rate {
initial_learning_rate: 0.004
decay_steps: 800720
decay_factor: 0.95
}
}
momentum_optimizer_value: 0.9
decay: 0.9
epsilon: 1.0
}
}
fine_tune_checkpoint: "ssd_mobilenet_v1_coco_2017_11_17/model.ckpt"
from_detection_checkpoint: true
num_steps: 100000
data_augmentation_options {
random_horizontal_flip {
}
}
data_augmentation_options {
ssd_random_crop {
}
}
}
train_input_reader: {
tf_record_input_reader {
input_path: "data/train.record"
}
label_map_path: "data/plate_number_map.pbtxt"
}
eval_config: {
num_examples: 30
max_evals: 10
}
eval_input_reader: {
tf_record_input_reader {
input_path: "data/test.record"
}
label_map_path: "data/plate_number_map.pbtxt"
shuffle: false
num_readers: 1
num_epochs: 1
}
Simpan file konfigurasi diatas dengan nama plate_number_v1.config kedalam folder training.
Konfigurasi diatas menggunakan batch_size=4 dan num_steps=100000 pada komputer penulis dengan spesifikasi 8 Core CPU, 1 GPU, dan RAM 16GB, nilai tersebut cukup berhasil untuk mendeteksi objek Plat Nomor, tapi sebaiknya nilai tersebut disesuaikan dengan spesifikasi komputer yang anda gunakan. Jika komputer yang anda gunakan mempunyai spesifikasi dibawah komputer yang penulis gunakan maka direkomendasikan untuk menurunkan nilai batch_size setidaknya batch_size=2 dan num_steps=140000.
Sampai ditahap ini kita sudah selesai menyiapkan semua file yang dibutuhkan pada saat training model object detection kita.
Note: Pastikan struktur direktori dan file dengan benar.
Berikut sususan akhir direktori yang penulis gunakan :
.
├── annotations
│ ├── test
│ │ ├── IMG-20180108-WA0115.xml
│ │ ├── ...
│ │ ├── IMG-20180108-WA0120.xml
│ │ └── IMG-20180108-WA0121.xml
│ └── train
│ ├── 100.E 6467 QW-09-20.xml
│ ├── ...
│ ├── 255.E 6527 OD-02-20.xml
│ └── 256.E 4572 SS-01-16.xml
├── data
│ ├── plate_number_map.pbtxt
│ ├── test.record
│ ├── test_labels.csv
│ ├── train.record
│ └── train_labels.csv
├── images
│ ├── test
│ │ ├── IMG-20180108-WA0115.jpeg
│ │ ├── ...
│ │ ├── IMG-20180108-WA0120.jpg
│ │ └── IMG-20180108-WA0121.jpg
│ └── train
│ ├── 100.E 6467 QW-09-20.jpeg
│ ├── ...
│ ├── 255.E 6527 OD-02-20.jpg
│ └── 256.E 4572 SS-01-16.jpg
├── training
│ └── plate_number_v1.config
├── generate_tfrecord.py
└── xml_to_csv.py
8 directories, 1016 files
Training Model
Setelah semua file yang dibutuhkan selesai dipersiapkan maka kita akan memasuki tahap training Neural Network untuk mengenali pola Tanda Nomor Kendaraan Bermotor (TNKB). Kita perlu menyiapkan TensorFlow Model dan menyalin berkas-berkas yang kita buat sebelumnya untuk kebutuhan proses training.
- Salin direktori
data,images, dantrainingyang kita buat sebelumnya ke dalam foldermodels/research/object_detection. - Setelah semua berkas sudah disalin kita akan menggunakan pre-trained model yang bernama
SSD Mobilnet v1dari COCO model tersebut bisa diunduh disini, jika sudah berhasil diunduh lalu ekstrakssd_mobilenet_v1_coco_2017_11_17.tar.gzkedalam direktorimodels/research/object_detection.
Jika kita melihat ke daftar COCO-trained Model maka akan ada banyak model yang tersedia dan silahkan pilih sendiri mana yang akan kita gunakan untuk training Neural Network kita, tapi penulis akan memilih yang tercepat yaitu ssd_mobilenet_v1_coco yang mana kecepatannya sampai 30/milisecond.
Baik! Mari kita mulai training Neural Network, jalankan perintah dibawah ini untuk memulai proses training.
$ python3 train.py \
--logtostderr \
--train_dir=training \
--pipeline_config_path=training/plate_number_v1.config
Tunggu sampai proses training selesai, dikomputer penulis sendiri membutuhkan waktu sekitar 12 sampai 13 jam untuk proses training ini
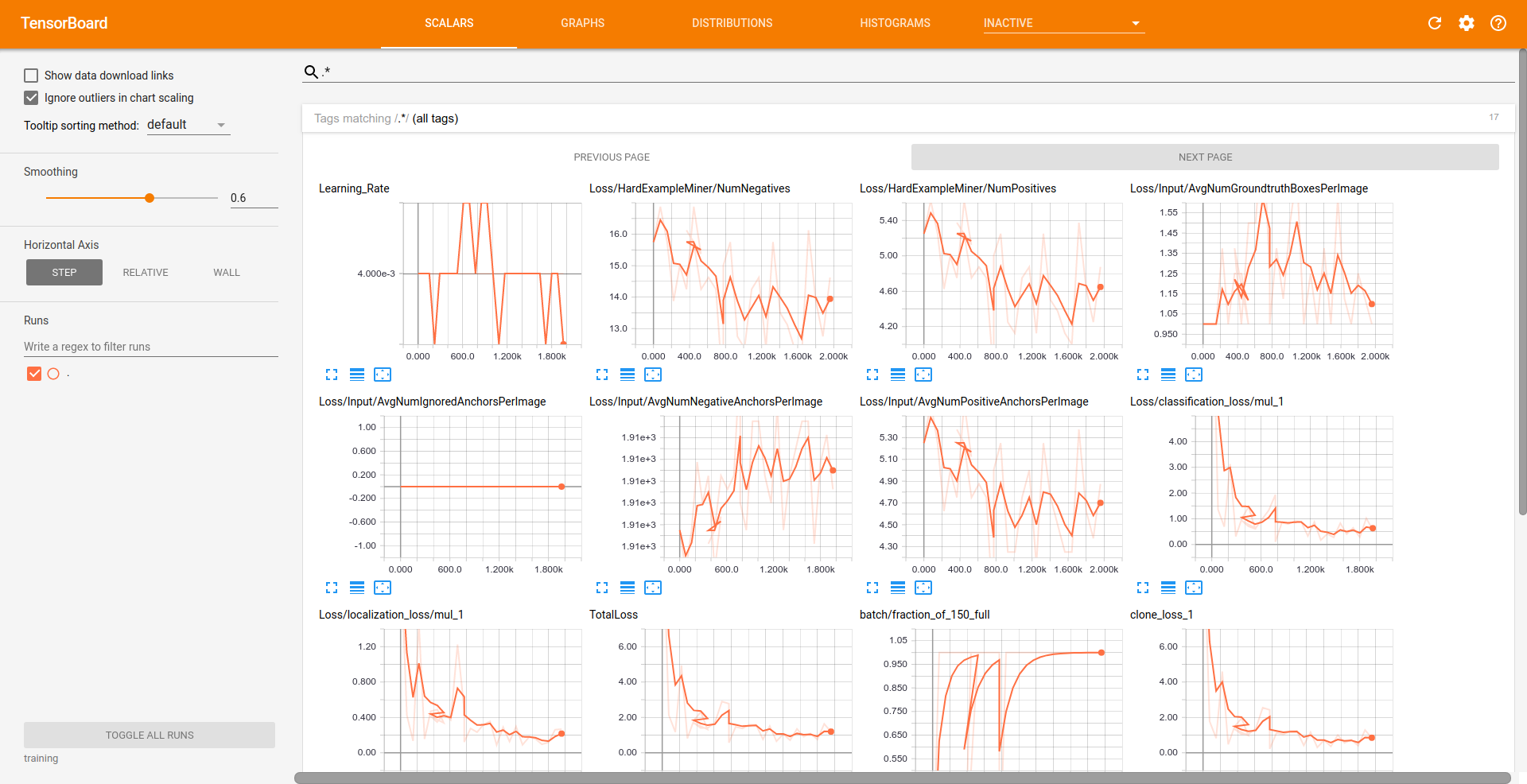
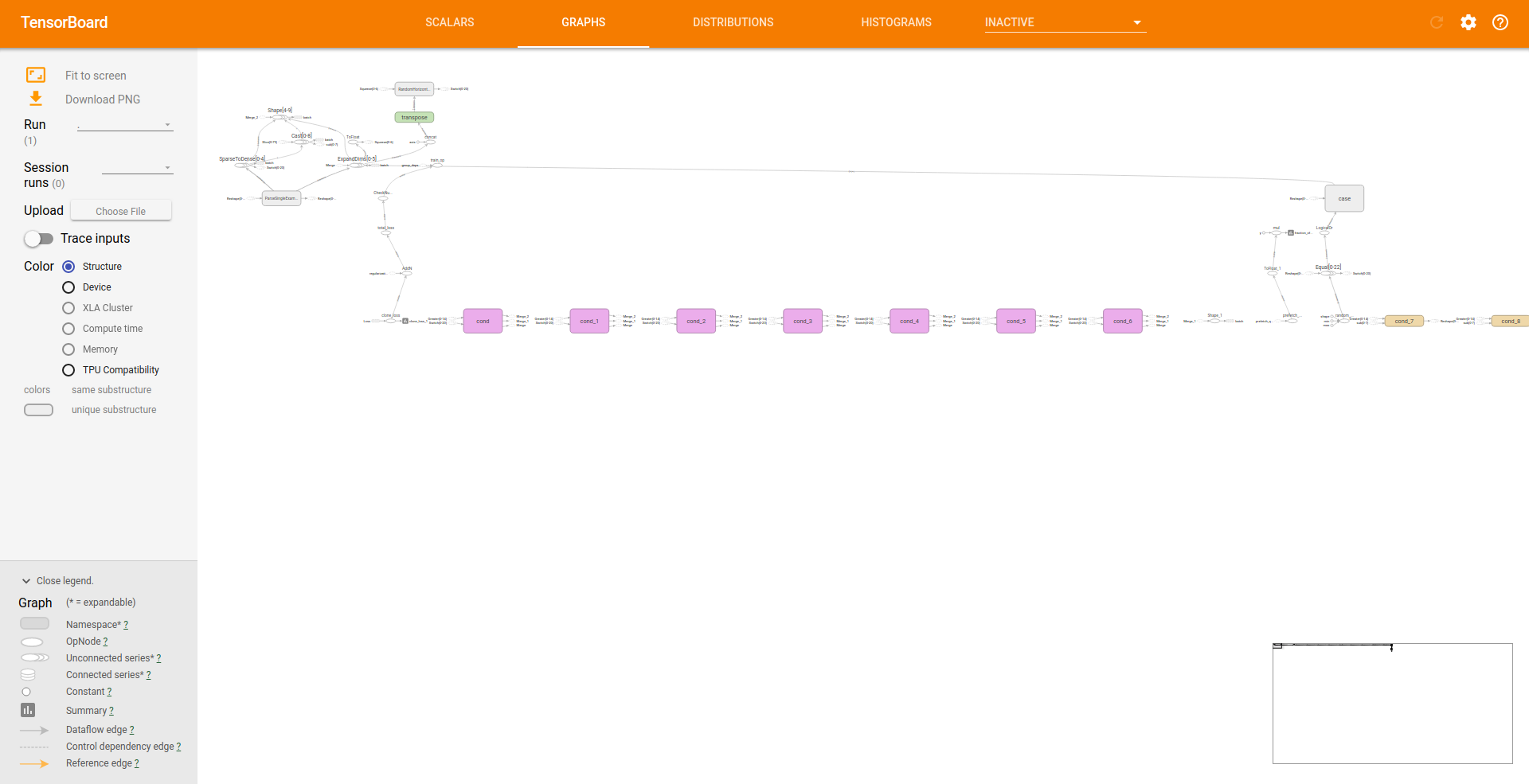
Grafik TensorBoard
Untuk melihat grafik selama proses training kita akan menggunakan TensorBoard, jalankan perintah dibawah ini untuk menjalankan TensorBoard.
$ tensorboard --logdir=training
Kurang lebih tampilan TensorBoard akan seperti dibawah ini
Evaluation / Testing
Proses ini untuk mengevaluasi hasil dari tahap proses training sebelumnya, boleh dilakukan boleh juga tidak tapi direkomendasikan proses ini tetap dilakukan agar model yang dihasilkan mendapatkan hasil yang bagus
$ python3 eval.py \
--logtostderr \
--pipeline_config_path=training/plate_number_v1.config \
--checkpoint_dir=training \
--eval_dir=evaluation
Export Graph
Proses training diatas belum sepenuhnya selesai karena tujuan utama dari proses training Neural Network adalah sebuah model yang akan kita gunakan untuk mendeteksi objek-objek yang telah kita masukkan sebelumnya, maka dari itu kita perlu mengekspor modelnya, jalankan perintah berikut untuk mengekspor model.
$ python3 export_inference_graph.py \
--input_type image_tensor \
--pipeline_config_path training/plate_number_v1.config \
--trained_checkpoint_prefix training/model.ckpt-100000 \
--output_directory plate_number_recognition_model_v1_2018_01_24
Mencoba Hasil Model
Ini adalah tahap terakhir yang kita lalui dan kita akan mencoba menggunakan model yang telah kita latih untuk mengenali Tanda Nomor Kendaraan Bermotor (TNKB) sebelumnya.
Tahap pengujian berikut ini membutuhkan sampel gambar yang berbeda dari gambar dataset yang kita gunakan pada proses training dan testing, maka kita perlu untuk mendapatkan sampel gambar, anda dapat mencarinya via Google Images atau bisa juga memotret langsung menggunakan kamera sendiri.
Taruh 2 sampel gambar kedalam direktori models/research/object_detection/test_images dan berikan nama image1.jpg dan image2.jpg atau replace gambar yang ada.
Pengujian via Jupyter Notebook
Untuk pengujian via Jupyter Notebook kita hanya perlu mengubah MODEL_NAME dengan model yang telah kita ekspor sebelumnya dan NUM_CLASSES menjadi nilai 1 karena hanya satu objek yang akan kita deteksi
Ubah kode berikut
MODEL_NAME = 'ssd_mobilenet_v1_coco_2017_11_17'
MODEL_FILE = MODEL_NAME + '.tar.gz'
DOWNLOAD_BASE = 'http://download.tensorflow.org/models/object_detection/'
PATH_TO_CKPT = MODEL_NAME + '/frozen_inference_graph.pb'
PATH_TO_LABELS = os.path.join('data', 'mscoco_label_map.pbtxt')
NUM_CLASSES = 90
Menjadi
MODEL_NAME = 'plate_number_recognition_model_v1_2018_01_24'
# MODEL_FILE = MODEL_NAME + '.tar.gz'
# DOWNLOAD_BASE = 'http://download.tensorflow.org/models/object_detection/'
PATH_TO_CKPT = MODEL_NAME + '/frozen_inference_graph.pb'
PATH_TO_LABELS = os.path.join('data', 'mscoco_label_map.pbtxt')
NUM_CLASSES = 1
Dan hapus bagian berikut ini karena kita tidak perlu mengunduh model ssd_mobilenet_v1_coco_2017_11_17 karena kita akan menggunakan model yang telah kita training sendiri
opener = urllib.request.URLopener()
opener.retrieve(DOWNLOAD_BASE + MODEL_FILE, MODEL_FILE)
tar_file = tarfile.open(MODEL_FILE)
for file in tar_file.getmembers():
file_name = os.path.basename(file.name)
if 'frozen_inference_graph.pb' in file_name:
tar_file.extract(file, os.getcwd())
Dan hasilnya kurang lebih akan seperti dibawah ini
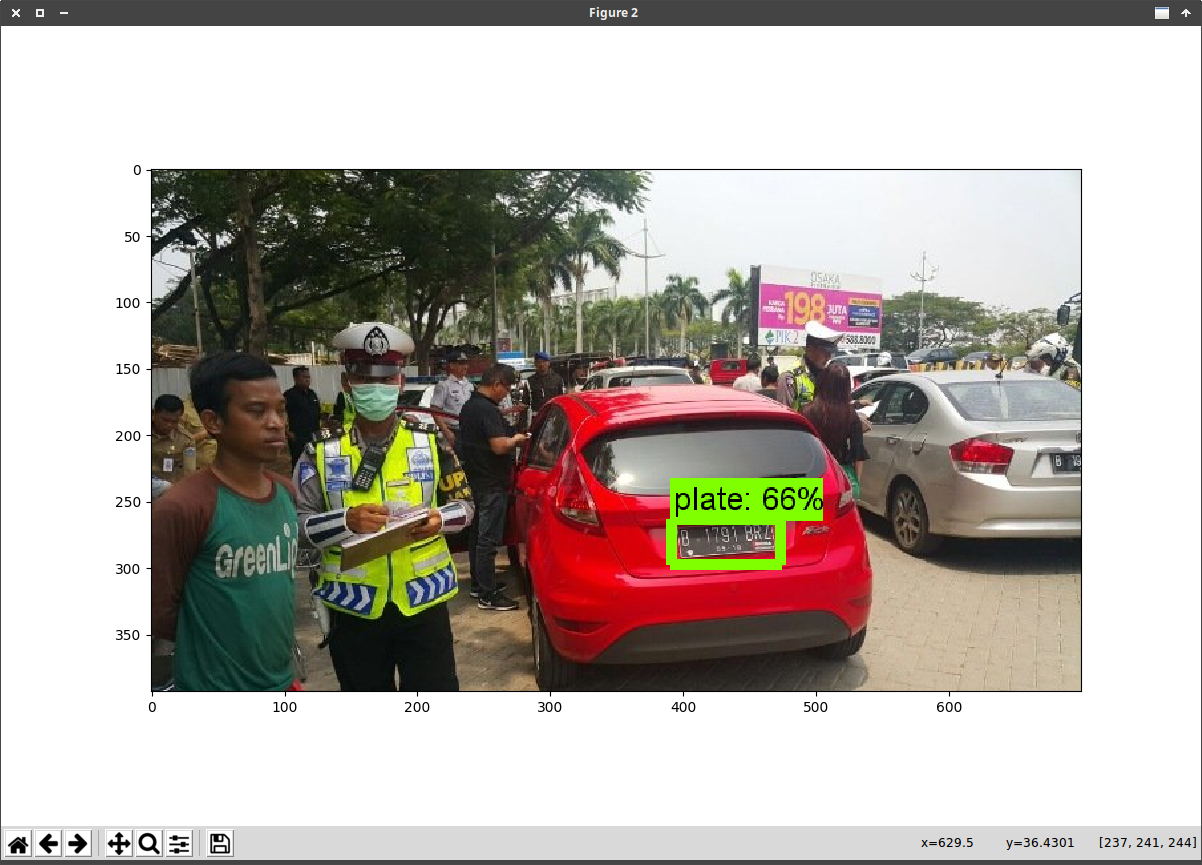
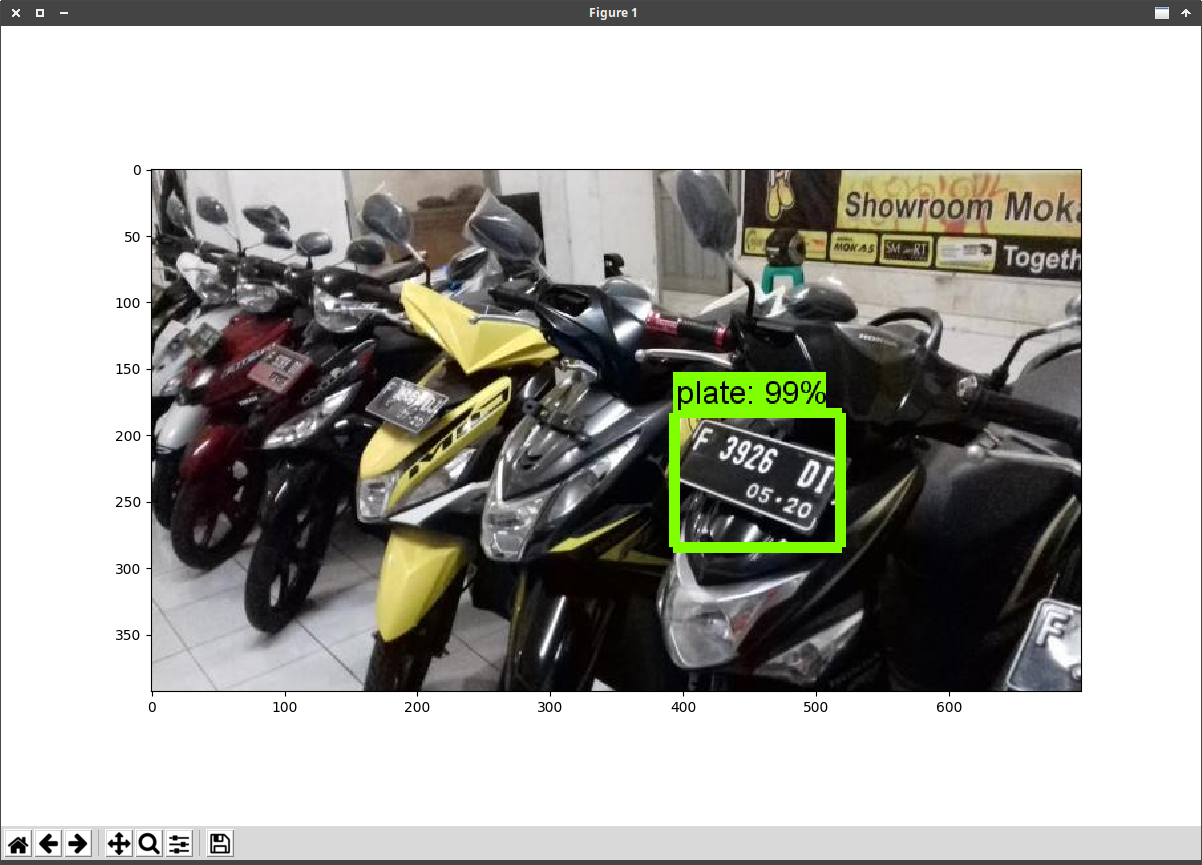
Pengujian via Webcam
Untuk pengujian model menggunakan webcam langkahnya sama seperti pada pengujian via Jupyter Notebook yaitu mengubah MODEL_NAME dan NUM_CLASSES kemudian kita hanya perlu menambahkan beberapa baris kode untuk menggunakan webcam melalui pustaka OpenCV, langkah ini sama seperti pada tutorial sebelumnya.